From STREAM v1.2 to the Rebuild Problem Definition
An analysis narrative — June 2026
Who this is for. People who were involved in building the original Paradigm 7 STREAM. It assumes you know the product. Its job is to walk, in order, from what we built → what the market became → the flaw we now name → where we’re pointing the rebuild → the problem we’re solving first. It is a reasoning trail, not a pitch: every turn is argued, and the uncomfortable conclusions are kept in.
1. What STREAM was
Section titled “1. What STREAM was”STREAM (2012 strategy; v1.2 shipping by 2016) was a data-integration and publication engine for capital-project and operations information. Its centre of gravity — then and now the thing worth keeping — was a small number of genuinely good ideas:
- The entity and scoped identity. An entity was source + identity + attributes,
where identity was a set of scoped identifiers (
tag → P-101,model → Plant/P-101, …). Entities sharing an identifier under the same scope were the same real-world thing and merged. - Reversible identity merge/split — the heart of the engine. Merge was transitive (a connected-components problem over a source/identity graph; the v1.2 code called it re-chaining) and, crucially, reversible: because every attribute and identifier remembered its source, withdrawing a source could un-merge entities that only that source held together. Conflicts were retained structurally — both values kept, each tagged by source — not last-writer-wins.
- Fluid, the transform DSL: sigils (
@attr,#scope,.prop), regex operators, entity operations including the selective-disclosure primitivesclear attribute/clear identifier, and importers (textParser,xlReader,databaseReader,dwgReader,rvmParser). - A units-aware type system — numbers carried units and arithmetic converted within unit groups and failed loudly across them.
- The changeset pipeline — interpret → transform → delta-analyse → apply/propagate — running recursively along subscriptions, which is what made the WIP→Published two-stage pattern work.
- Interpretation skinning — raw entities warehoused once, an interpretation config (“skin”) applied at query time, so different audiences saw different views of the same data without forking the model.
- CAD/3D as first-class data — the January 2013 demo showed tag ↔ 2D P&ID ↔ 3D model as one entity seen three ways.
Two diagrams from the 2013 “Under the Hood” dev blog make the engine concrete. They depict the v1.2 implementation — historical reference — but the concepts are exactly what the rebuild carries forward:
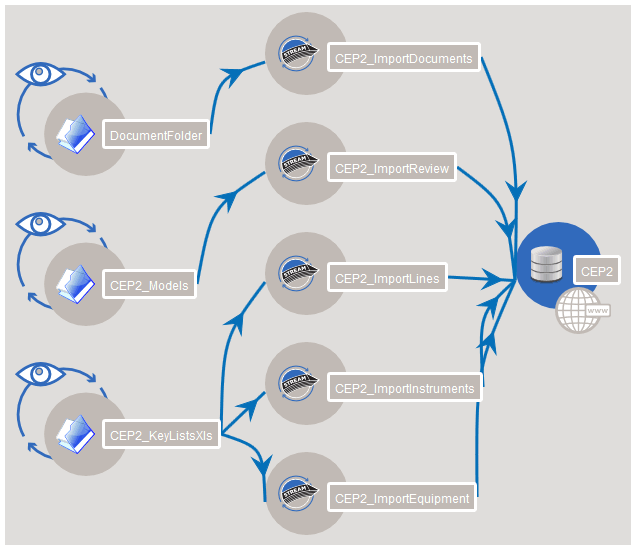
Multi-source convergence: documents, 3D models and key lists are watched at source, each flows through its own import module, and all converge into one store — the many-sources-to-one-entity unification the reconciliation engine exists to perform.
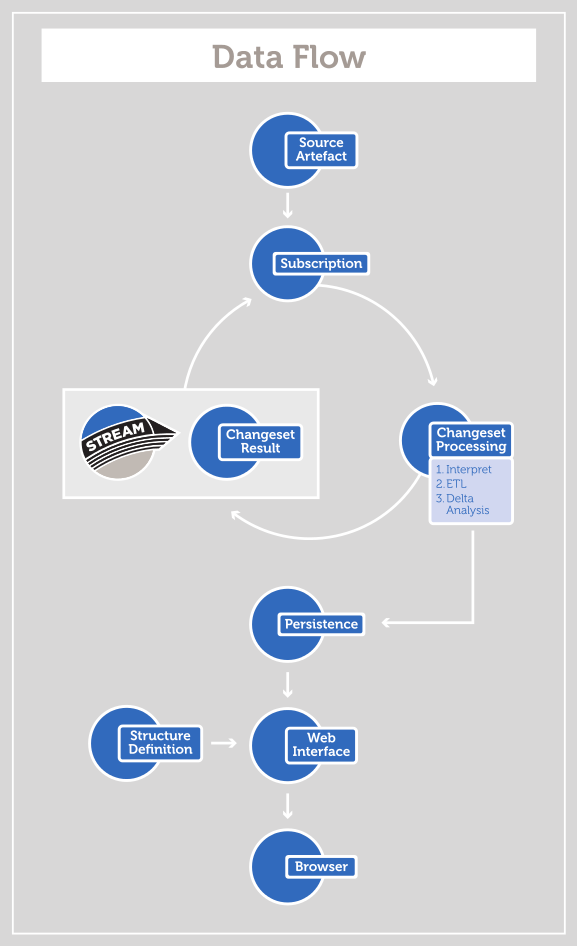
The changeset pipeline: a source change fires a subscription, runs Interpret → transform → Delta analysis, loops the changeset result back, then persists and surfaces it — the same four-step, subscription-triggered engine described above.
STREAM also put a face on the payoff: a validated equipment report that flagged, per item, what was present, missing or conflicting across the contributing sources — the data-quality view the rebuild re-centres on (pictured in the solution definition).
The ideas were real, but the product never reached a production EPC deployment. The closest engagement — the AMEC “Zektin” HAZID work (late 2013) — was built on entirely different technology; STREAM’s intended role there was to feed the most accurate available information into the HAZID facilitation meetings, not to be deployed as the EPC’s system. STREAM was, in honest terms, a strong set of ideas and a working demonstration that did not cross into production. The ideas above are the part worth carrying forward; the original stack (Windows-only Service Host + ASP.NET MVC/IIS + Windows auth + SQL Server/MongoDB) is not a constraint on the rebuild, and the technology choices are deliberately reopened in §4.
2. The flaw we now name
Section titled “2. The flaw we now name”STREAM was sold primarily as a data-handover tool from the EPC to the client — a chargeable delivery service. That positioning had a structural defect we can now state cleanly:
The party who paid was harmed by the very thing the product did.
The EPC, the buyer, did not want clean, early, transparent handover. It benefited from obfuscating data inconsistencies and from delaying handover. The party who actually wanted data consistency — the asset owner — did not control the purchase. No amount of product quality fixes a value proposition in which the buyer’s rational incentive is for the tool to under-deliver. And the owners who did benefit were typically very large corporates who favour established vendors — a hard first market for a small product.
This is not a sales-execution lesson. It is a positioning error, and it is the single most important thing the rebuild changes.
3. What the market became (2026 current-state analysis)
Section titled “3. What the market became (2026 current-state analysis)”The 2012 competitive landscape has consolidated and moved up into heavyweight digital- twin platforms:
- AVEVA — taken fully private by Schneider Electric; all-in on CONNECT, an Azure-based “industrial intelligence” platform (Asset Information Management + PI real- time data), with NVIDIA Omniverse / OpenUSD partnerships.
- Hexagon — the lineage of the Intergraph SmartPlant competitor we named in 2012. Its Asset Lifecycle Intelligence division (including SDx, an EPC→owner handover product) was spun out as Octave, an independent ~$1.6B-revenue pure-play software company listed in May 2026. Our most direct descendant-competitor is now focused and well-capitalised.
- Bentley — pivoted to iTwin as a developer platform (PaaS), infrastructure- focused (water, rail, utilities), courting “digital integrator” partners.
- Cognite (~$1.6B valuation) — “industrial DataOps”; Data Fusion builds a contextualised industrial knowledge graph. Its mechanism is essentially our identity- merge idea, rebranded as data-fabric / knowledge-graph and aimed at agentic AI.
And a mid-tier worth knowing, because it shows where the value has fragmented:
- DIGATEX — AI/ML extraction of legacy 2D documents into tag/asset registers (digitise-the-past-once; substantially a service).
- Datum360 — class-library / engineering-information governance — acquired by Autodesk. The clearest signal in the scan: that layer is valuable enough that platform giants buy it.
- Cenosco (asset integrity), Aize (collaborative ops), Cintoo (reality capture) — adjacent wedges.
The uncomfortable conclusion. STREAM’s 2012 differentiator — “we merge data from many sources into one view” — is now table stakes. Every platform above markets it. STREAM cannot win as “another data-unification platform.”
What survives as genuinely defensible is narrower and sharper than the original pitch:
- Reversible, provenance-true merge/split with structural conflict retention. The knowledge-graph incumbents largely do last-writer-wins or manual stewardship. “Keep both values, tag each by source, un-merge when a source is withdrawn, treat a human correction as just a highest-priority source” remains distinctive.
- Interpretation skinning — one warehouse, many audience-specific views.
- Co-equal scoped identity — see §4; this one we under-sold in 2012.
quadrantChart
title Where the tools sit — and STREAM's wedge
x-axis Snapshot / one-time --> Continuous / live
y-axis Single source of record --> Cross-source reconciliation
quadrant-1 Live reconciliation
quadrant-2 Batch reconciliation
quadrant-3 Batch record
quadrant-4 Live record
STREAM: [0.85, 0.9]
Twin platforms: [0.72, 0.6]
GIS / CMMS: [0.72, 0.18]
Datum360: [0.3, 0.55]
DIGATEX: [0.22, 0.32]
The wedge in one picture: STREAM occupies the continuous + cross-source reconciliation corner the others don’t. Extraction (DIGATEX) and class libraries (Datum360) are batch and record-centric; the platforms reconcile but lean last-writer-wins; GIS/CMMS are single systems of record.
4. The repositioning
Section titled “4. The repositioning”The rebuild is positioned as a reconciliation & assurance layer: the runtime “trust layer” that ingests every source, reconciles them deterministically with conflict retention and provenance, surfaces what’s missing and inconsistent, and feeds a trusted core to whatever digital twin / GIS / CMMS the owner already runs. It complements the heavyweight platforms rather than fighting them — extraction tools (DIGATEX) and class libraries (Datum360) become inputs, not rivals.
The promise reduces to four C’s: continuity, consistency, completeness — and therefore confidence. Reconcile every source continuously, make the record consistent and as complete as the task demands, and the owner can finally trust what it knows well enough to manage by risk.
| From the original | In the rebuild |
|---|---|
| Keep: reversible merge/split, conflict retention, interpretation skinning, units-aware types, scoped identity | These are the engine and the moat. Specify and test merge/split first — it is the highest-risk behaviour to get right, and everything else rests on it. |
| Drop: the EPC-handover selling motion; Windows/IIS/ASP.NET-only stack | Sell to the owner directly; stack and hosting are open decisions. |
Re-cast: selective disclosure (clear attribute/clear identifier; originally “IP filtering”) | No longer “hide data from the client.” Now inbound curation — ingest messy contractor/vendor data and reconcile it into a trusted core. Same mechanism, honest framing. |
| Open: Fluid-vs-embedded-language; persistence model; hosting (SaaS vs self-host) | Deliberately undecided; to be resolved in the solution definition. |
One differentiator we previously under-sold. Most tools — then and now — identify an asset in a single “language,” usually the engineering tag, and treat common operational names as second-class. STREAM’s scoped-identity model makes the engineering tag, the operational common name, the GIS feature ID and the SCADA point all co-equal, first-class merge keys. For a water operations buyer who navigates by street names and nicknames, not tags, that is not a detail — it is the difference between a system they can use and one they can’t.
5. The new beachhead — Australian water
Section titled “5. The new beachhead — Australian water”Not the large corporates that beat us last time. Australian water, the tier below the metro majors (Sydney Water, Melbourne’s retailers, SA Water, Water Corporation): the regional urban water corporations and council-run utilities — Victoria’s Barwon, Coliban, Goulburn Valley and North East Water; the 89 NSW council Local Water Utilities serving 1.8M people outside Sydney/Hunter (Central Coast, Tamworth Regional, Riverina Water); TasWater; and South-East Queensland (Seqwater bulk water above the distributor-retailers Urban Utilities and Unitywater and the council-run water businesses City of Gold Coast, Logan and Redland). The target asset is the brownfield network already in service whose own data quality is unknown — which suits the reversible engine far better than greenfield handover ever did. It is, literally, a “tell me what I actually know about assets I’m already operating” machine.
Initial go-to-market focus is South-East Queensland, where near-term access is warmest:
the first conversations target the SEQ providers — beginning with City of Gold Coast and the
distributor-retailers — with the rest of the tier as the expansion path. (Full named
examples and the tier definition are in problem-definition.md.)
Why this is clear and feasible:
- Aging assets are failing measurably — national median >12.7 main breaks per 100 km per year; much of the network past design life — and the sector is being pushed toward risk-based, data-led renewal.
- The spearhead risk story is asbestos-cement (AC) pipe. Vast mid-century AC mains are past design life; the industry body (WSAA) is pushing risk-based management; yet the sector openly admits its records are incomplete and contradictory — guidance literally says AC registers must carry “confidence levels when information is incomplete,” and that two surveys of the same network can disagree once data passes between contractors, councils and consultants. That is our engine, described in the customer’s own words. And the failure mode is not tidy-data nicety — it is service-continuity and asbestos-exposure risk.
- A converging compulsion to “know your assets”: economic regulators (IPART, ESC) tying prices to demonstrated asset management; public benchmarking (BoM National Performance Report); drinking-water safety (NSW Health); asbestos rules (WSAA).
- Home-market fit, and a tier the incumbents under-serve: even Sydney Water concedes the foundational job is assembling and reconciling asset information (it is spending years 1–5 building an “asset information model” and “common data environment”). The majors validate the direction; the feasible buyer is the tier beneath them, which has the same problem and none of the capacity.
Mid-tier private industrial was examined and dropped — nearer the incumbents’ core, with no regulatory forcing function.
The re-education caveat: these buyers have low data maturity and must be shown why consistency matters. The gap report that reveals their problem is therefore part of the product, not just the marketing.
6. The problem definition
Section titled “6. The problem definition”All of the above converges on a single problem statement, written up in full in
problem-definition.md. In one paragraph:
An Australian regional / mid-sized water utility cannot trust what it knows about the assets it already operates. The same main, pump or valve is described across GIS, the asset system, EDRMS, SCADA, contractor surveys and paper as-builts — sources that disagree, are incomplete, and record neither which is right nor where they came from — and most tools make this worse by privileging the engineering tag and demoting the names operators actually use. It is being told to manage that network by risk, but its risk model is only as trustworthy as records that contradict each other. No existing tool offers it continuous, reversible, provenance-true reconciliation that says plainly what we know, what we don’t, and who said so.
Where this goes next
Section titled “Where this goes next”This narrative and the problem definition are parts 0 and 1 of the solution specification. NExt: the solution definition (what STREAM does about it and the shape of the answer) and the requirements (what must be built and proven — starting with merge/split, the highest-risk behaviour, specified and under test).
Sources for the 2026 current-state analysis are linked inline in the problem definition and were gathered from public vendor and regulator material (AVEVA/Schneider, Hexagon/ Octave, Bentley, Cognite, DIGATEX, Datum360/Autodesk; Ofwat, IPART, BoM, NSW Health, WSAA) in June 2026.