Solution Definition
Status: Draft · Part 2 of the solution specification · June 2026
Built from the problem definition. It answers what STREAM does about that problem and the shape of the answer. The three open technology decisions — DSL, persistence, hosting — are deliberately deferred to the requirements; see §8.
1. The solution in one line
Section titled “1. The solution in one line”STREAM is the reconciliation & assurance layer for an asset owner’s data. It extracts and transforms the sources that describe the network — structured and semi-structured data (text files, spreadsheets, databases) as a core capability, harder unstructured sources via specialist extractors — reconciles them deterministically into one picture (retaining conflicts with their provenance rather than overwriting them), and states plainly what we know, what we don’t, and on whose authority. It then feeds that trusted core to whatever digital twin, GIS or CMMS the owner already runs.
The headline verb is reconcile, but reconciliation rests on owning extract and transform too. STREAM does not merely store, and it is not a twin or a class library; it makes the owner’s systems trustworthy.
That promise resolves into four C’s, and the first three earn the fourth: continuity — every source reconciled continuously, not in a one-off migration; consistency — the same asset tells one story, with disagreements surfaced rather than buried; and completeness — what’s known and what’s missing, stated for the use at hand. Together they yield confidence: data an owner can act on under a risk-based regime. Continuity, consistency, completeness — and therefore confidence.
2. The core mechanism — reversible identity merge/split
Section titled “2. The core mechanism — reversible identity merge/split”Everything else rests on one mechanism, so it is specified and tested first.
- Scoped, co-equal identifiers. The engineering tag, the operational common name, the GIS feature ID and the SCADA point are all first-class merge keys. There is no privileged “master” identifier — the operator’s vocabulary is as load-bearing as the engineer’s.
- Transitive merge. Entities sharing an identifier under the same scope are the same real-world thing. Merge is transitive: if A and B share a tag and B and C share a model ID, then A, B and C collapse into one entity even though A and C share nothing directly. Internally this is a connected-components problem over a source·identity graph.
- Structural conflict retention. When sources disagree on a value, both are kept, each tagged with its source — not last-writer-wins. Disagreement is surfaced, not silently resolved.
- Reversibility. Because every attribute and identifier remembers which source contributed it, withdrawing a source (a deleted file, a retired system) un-merges the parts it alone held together: the entity splits back into what the remaining sources imply. Merge and split are the same algorithm run forward and backward — this is what lets the picture self-correct as sources change instead of accumulating stale unifications.
Why first: assurance reporting, corrections, delta propagation and interpretation skinning all sit on top of this. It is also the subtlest behaviour to get right and was the least-tested part of the original engine — so the rebuild pins it down, with tests, before building anything on it.
flowchart TB
subgraph ENT["One entity = one connected component"]
A(["Source A"]):::source --- T["id — tag: P-101"]:::idnode
B(["Source B"]):::source --- T
B --- M["id — model: /P101"]:::idnode
C(["Source C"]):::source --- M
end
subgraph LEGEND["Legend"]
direction LR
lsrc(["Source contribution"]):::source
lid["Shared identifier"]:::idnode
end
classDef source fill:#dbeafe,stroke:#2563eb,color:#1e3a5f;
classDef idnode fill:#fef3c7,stroke:#d97706,color:#7c2d12;
Merge: A and C share no identifier directly, but B bridges them (it carries both the tag and the model id), so all three collapse into one entity. Merge is transitive.
flowchart TB
subgraph E1["Entity 1"]
A(["Source A"]):::source --- T["id — tag: P-101"]:::idnode
end
subgraph E2["Entity 2"]
C(["Source C"]):::source --- M["id — model: /P101"]:::idnode
end
X["Source B withdrawn<br/>(deleted file / retired system)"]:::gone
subgraph LEGEND["Legend"]
direction LR
lsrc(["Source"]):::source
lid["Identifier"]:::idnode
end
classDef source fill:#dbeafe,stroke:#2563eb,color:#1e3a5f;
classDef idnode fill:#fef3c7,stroke:#d97706,color:#7c2d12;
classDef gone fill:#fee2e2,stroke:#dc2626,color:#7f1d1d,stroke-dasharray:5 3;
Split: withdraw the bridging source B and the connected component re-partitions into two entities. Merge and split are the same computation, run forward and backward.
3. What the owner gets — the assurance outputs
Section titled “3. What the owner gets — the assurance outputs”The point is not a tidy warehouse; it is a trustworthy answer to “what do we actually know about this asset, and how much of it can we trust?” Three concrete outputs:
A. The trusted picture (provenance + uncertainty). For any asset, one view that assembles every source’s contribution, tags each value with where it came from, makes agreement and disagreement explicit, and shows gaps as gaps rather than as blanks. The plain-language promise — what we know, what we don’t, who said so — is delivered literally.
B. Gap & conflict reporting. A report across a class of assets that flags, per item, what is present, missing, or conflicting across sources. This turns “we think our records are bad” into “here are the 412 items with conflicting design pressure and the 1,300 missing a datasheet.” For a low-data-maturity buyer it is both the value and the re-education tool — it shows them their problem in their own data.
A report runs the interpretation skin’s validation templates (what should be present for each class) over the reconciled data (what is, with its conflicts and provenance) — so it is computed on the reshaped view, and a different skin produces a different report (see §4 and §8).
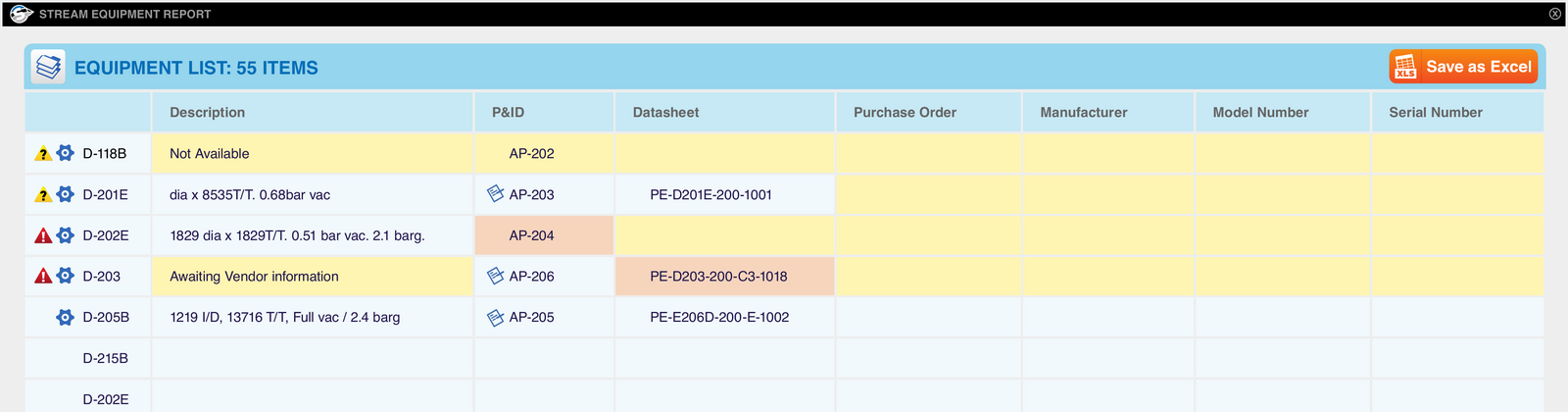
The data-quality view: per-item status icons and colour-coded missing (yellow) and conflicting (orange) values across P&ID, datasheet, purchase-order and vendor columns, with one-click Excel export. (2013 prototype mockup — illustrates the intended output.)
C. Corrections as a highest-priority source. When a person resolves a conflict, the correction is captured as just another source — given top priority — with a reason (multiple values / updated source / free text) and provenance (by whom, when). The originals stay intact and traceable; the trusted picture simply shows the corrected value as authoritative. This falls straight out of the engine: source priority/authority is the same mechanism behind both manual corrections and automated “updated-source-wins” rules.
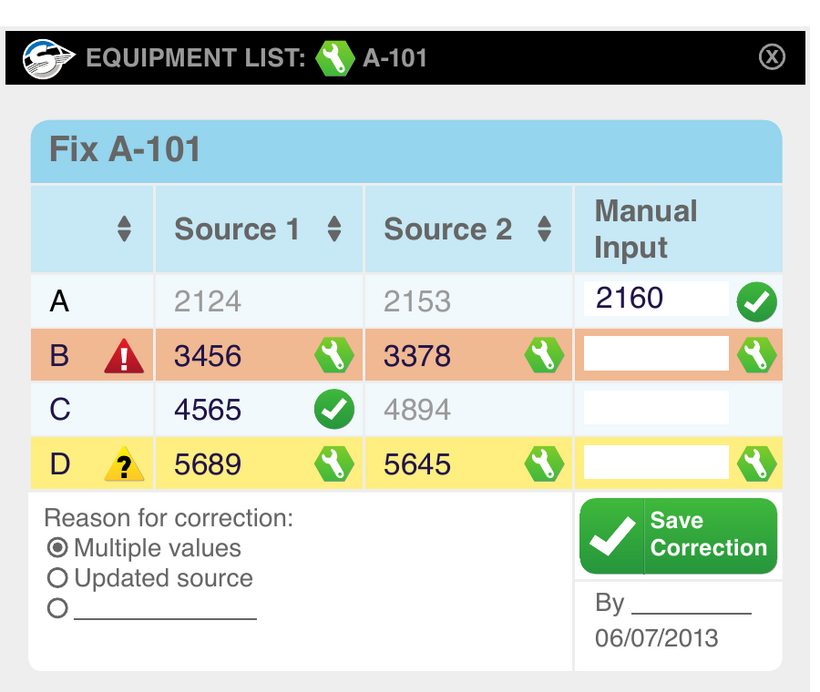
Corrections reconcile one asset’s attributes by showing every contributing source side by side, flagging conflicts, and capturing a manual value with a reason and author. (2013 prototype mockup — designed in the original, a first-class capability in the rebuild.)
Quality is skin-relative — by design. Because reports run on the reshaped view (§4, §8), the quality metrics an owner sees — completeness, consistency, validity — are computed for a given skin/use, not as one global score. The reconciliation beneath is objective: attribute X has these values, from these sources, and they agree or they don’t. But how that rolls up depends on the skin: a missing or conflicting X dents completeness only if that skin requires X, and carries the severity that skin assigns (Ignore / Warn / Error); a value two sources dispute may count as “present (with warning)” under one skin and “not yet reliably present” under a stricter one. So the same reconciled data can be “good enough for shutdown planning” under one skin and “not good enough for a regulatory asset-maturity submission” under another — and STREAM answers both from one foundation. There is no single global “data quality %”; quality is always quality for a use.
flowchart LR
STORE[("Raw reconciled store<br/>same data · same conflicts")]:::store --> SA["Skin: Operations"]:::skin
STORE --> SB["Skin: Regulatory maturity"]:::skin
SA --> RA["Report A<br/>completeness 92%<br/><br/>Good enough for shutdown"]:::good
SB --> RB["Report B<br/>completeness 41%<br/><br/>Not yet good enough"]:::bad
classDef store fill:#e2e8f0,stroke:#475569,color:#1e293b;
classDef skin fill:#fef3c7,stroke:#d97706,color:#7c2d12;
classDef good fill:#dcfce7,stroke:#16a34a,color:#14532d;
classDef bad fill:#fee2e2,stroke:#dc2626,color:#7f1d1d;
One store, two skins, two fit-for-purpose answers — quality is computed per use, not as a single global score.
4. Interpretation skinning — one warehouse, many audiences
Section titled “4. Interpretation skinning — one warehouse, many audiences”Rather than forcing a fixed schema in the ETL layer, STREAM warehouses raw reconciled entities and applies an interpretation configuration (“skin”) at query time. A skin defines how attributes are interpreted (scalar values vs links to other entities), the classification/plant-breakdown structure to surface, and attribute display names, grouping, ordering, visibility and validation templates.
Because the skin sits in the read path, everything a consumer sees — queries, reports and validation included — is computed on this reshaped view, not on the raw reconciled store directly (the layering is set out in §8).
Different audiences see different skins of the same data. An operations user planning a shutdown — navigating by street names and asset nicknames — sees different links, structures and groupings than an engineer looking at the same asset by tag. This is what lets one deployment serve multiple disciplines and business functions without forking the underlying data, and it is administered separately from the data flow and portable as a config package.
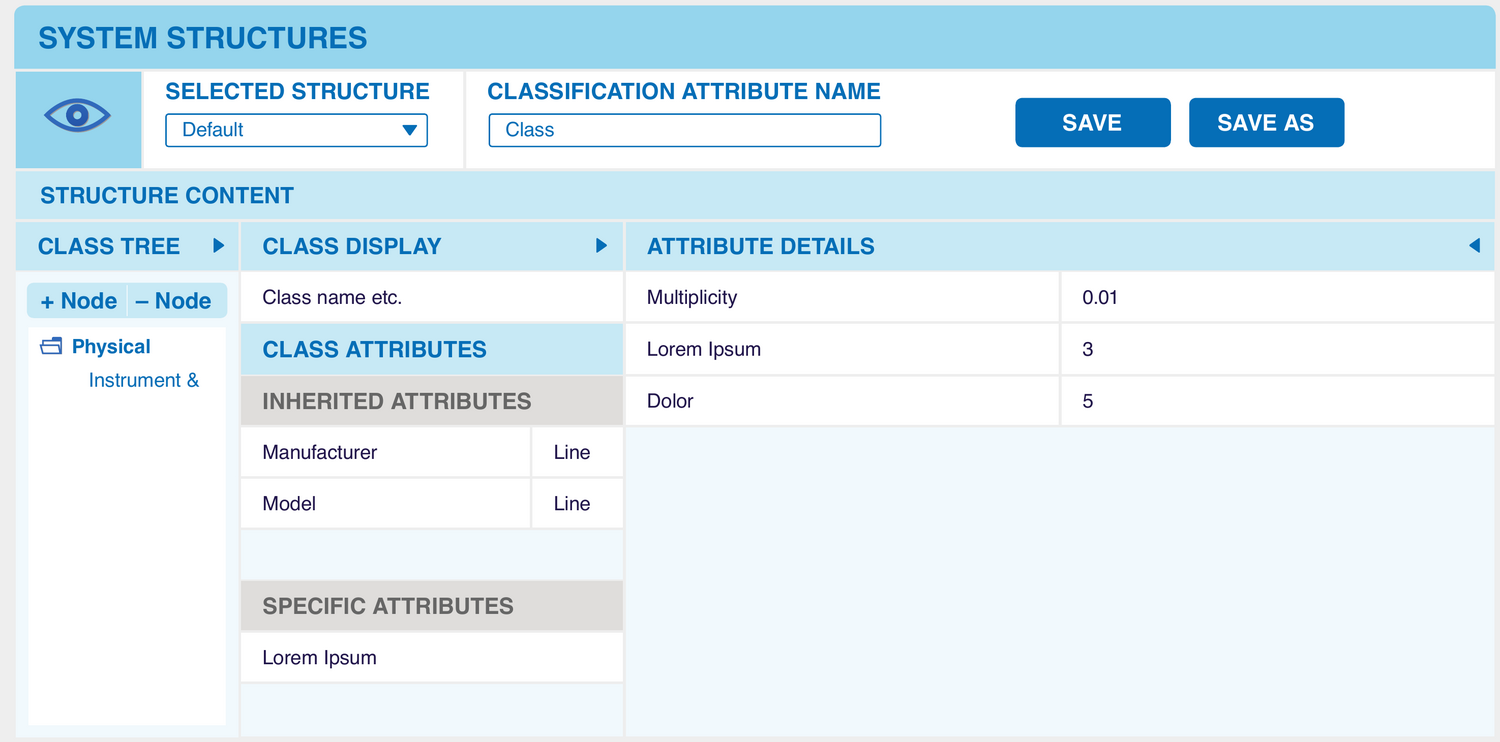
The interpretation-skin editor: classification tree, inherited vs specific attributes, and per-attribute rules (e.g. multiplicity). (2013 prototype mockup.)
5. Extract, transform, and integrate
Section titled “5. Extract, transform, and integrate”Reconciliation is only as good as what is fed into it, so identifying, extracting, massaging and refining the sources is itself a large part of the solution — not a thin adapter bolted on the front. STREAM retains extract-and-transform as a core function.
Owned — foundational extract & transform over structured and semi-structured sources.
Text-based data files, spreadsheets, and databases (the original engine’s textParser,
xlReader and databaseReader lineage) are read, parsed, cleaned, unit-coerced, validated,
and mapped to entities by the transform layer. This is core capability, not outsourced — it
is where much of the real work of making a source trustworthy happens.
Augmented — specialist unstructured extraction, via third parties where it makes sense. For the hard cases — scanned legacy documents, 2D drawings, P&IDs — STREAM augments with third-party AI/ML extraction specialists rather than trying to out-build them, consuming or orchestrating their output. Those extractors, and existing class libraries (e.g. Datum360/CLS360), are feeds into the reconciliation engine, not competitors to it.
Out — the trusted core. The reconciled result is exposed to the owner’s digital twin (Bentley iTwin, Cognite, etc.), GIS, CMMS, reports, file exports, and a query API. STREAM complements the systems the owner already runs and asks them to rip nothing out — which is what keeps the wedge sharp and the sale non-threatening.
6. Selective disclosure / inbound curation
Section titled “6. Selective disclosure / inbound curation”The same transform-time capability that once stripped proprietary IP on the way out (a
Fluid script omits attributes it does not map, and can explicitly redact with clear attribute / clear identifier, gated on a condition) is re-cast for the owner as curation
on the way in: decide, with an auditable policy, what from a messy vendor or contractor
handover is allowed to enter the trusted core. Same mechanism, honest framing — a
higher-level, reviewable disclosure/curation policy on top of the raw primitives is an
improvement to design in.
flowchart LR
IN["Inbound data<br/>vendor / contractor handover"]:::source --> POL{"Curation policy<br/>(auditable)"}:::engine
POL -->|"map & admit"| CORE[("Trusted core")]:::store
POL -->|"redact / omit"| DROP["Withheld<br/>(logged)"]:::gone
classDef source fill:#dbeafe,stroke:#2563eb,color:#1e3a5f;
classDef engine fill:#e0e7ff,stroke:#4f46e5,color:#312e81;
classDef store fill:#e2e8f0,stroke:#475569,color:#1e293b;
classDef gone fill:#fee2e2,stroke:#dc2626,color:#7f1d1d,stroke-dasharray:5 3;
Inbound curation: every item from a messy handover is either mapped into the trusted core or withheld — and the decision is logged.
7. What STREAM is NOT
Section titled “7. What STREAM is NOT”The boundaries are what keep the wedge defensible:
- Not an unstructured-document-OCR vendor. STREAM owns foundational extract & transform over structured and semi-structured data (§5), but it does not try to out-build the AI specialists on scanned drawings and P&IDs — it augments with them where it makes sense, and treats their output as a feed.
- Not a class library / requirements register — that is a feed, and it is being rolled up by the platform players.
- Not a digital-twin or visualisation platform — STREAM feeds those.
- Not a single system of record — GIS and CMMS each are one; STREAM reconciles across them and is not a replacement for any one of them.
8. The shape of the answer
Section titled “8. The shape of the answer”Preserve the shape the original proved; reopen the technology.
Keep the separations — but note they are layered, not parallel (the part that was right):
- Data-flow tier (write path) — extract, transform, reconcile and propagate changes via subscriptions and a changeset pipeline (extract/interpret → transform → delta → apply/propagate). Its output is the raw reconciled store: entities carrying every source’s contribution, with conflicts retained and provenance intact.
- Interpretation tier (read path) — applies the skin at query time: classification, attribute display and link-interpretation, and validation templates. It sits on top of the raw store and reshapes it into an audience-specific view.
- Query & reporting tier — built on top of the interpretation tier: queries, reports, exports and APIs run against the interpreted (skinned) view, not the raw store directly. A report’s columns, classification and pass/fail validation come from the skin (what should be there); the conflicts and provenance it colour-codes come from the raw reconciliation beneath (what is, and who said so).
A direct consequence: the same reconciled data under two different skins yields two different reports — different columns, structure, different judgments of what counts as “missing”, and therefore different completeness, consistency and other quality metrics (§3). Reporting is done on reshaped data, never on the raw consolidation alone.
Reopen the technology — three decisions are explicitly OPEN and routed to the requirements / architecture phase (noted here only so they are not mistaken for settled):
- DSL — keep a custom transform language (Fluid) vs embed a mainstream language (Python / Lua / JS).
- Persistence — document / relational / graph / hybrid (the merge/split mechanism is a graph problem, which will bear on this).
- Hosting — SaaS / single-tenant cloud / self-host (bears on the security model, which the original tied to Windows/AD).
9. Why this shape fits the beachhead
Section titled “9. Why this shape fits the beachhead”For the Australian regional / mid-sized water owner (problem definition, SEQ first):
- The gap report is the wedge and the re-education. It shows a low-maturity buyer their own problem before asking them to invest — exactly the “this is becoming important, tackle it now” entry the regulatory direction rewards.
- Brownfield-of-unknown-quality is the engine’s home turf. Reversible merge/split over contradictory, source-tagged records is precisely “tell me what I actually know about assets I’m already operating.”
- Complements, doesn’t compete. A buyer with no capacity for a multi-year, big-vendor programme can adopt a layer that feeds — rather than replaces — its existing GIS/CMMS and any future twin.
- Co-equal naming serves operations. Operators navigate by common names, not engineering tags; making both first-class is the difference between a system they will use and one they won’t.
Foundational inclusions for the beachhead — validate early
Section titled “Foundational inclusions for the beachhead — validate early”A first-cut starter set for Australian water, grounded in the systems and standards these utilities actually run. This is a candidate list to confirm through discovery with the SEQ beachhead utilities early in product development — not a locked specification. The exact systems, schemas and priorities vary by utility and must be validated before connectors and default skins are built; treat finalising this set as one of the first product-development tasks.
Source types to connect first — the common AU water stack is “billing, financial, work-order (CMMS), GIS, SCADA, CIS, LIMS”:
- GIS — Esri ArcGIS is dominant; its Water Distribution Utility Network Foundation already supplies asset groups, types and attributes (material, diameter, install date, status). Usually the spatial backbone and primary asset register.
- EAM / CMMS — work orders, maintenance history, condition. In the council/regional tier: TechnologyOne and Assetic are common, plus IBM Maximo, Infor/Hansen, Cityworks.
- SCADA / telemetry, hydraulic models (InfoWorks WS Pro/ICM, Bentley WaterGEMS/SewerGEMS), spreadsheets & databases (ad-hoc registers — STREAM’s owned extract aims squarely here), EDRMS / CAD / scanned as-builts, condition surveys & LIMS.
Standards to seed classification & attribute templates — Esri’s Water Utility Network Foundation data model; WSAA codes (WSA 03 Water Supply, WSA 02 Sewerage) and the WSAA/BIM4Water/Uniclass classification work; ISO 55000/55001 (condition, criticality, performance); AS 5488 (subsurface-utility location confidence levels).
Foundational skins to seed — each defines its own classification and templates, and therefore its own completeness/consistency metrics (§3):
- Operations / maintenance — navigate by location and common name; criticality, condition, isolation valves, work history (shutdown planning, low points and drains).
- Capital planning / renewal — age, material, install date, condition, break/failure history, criticality → risk-based renewal prioritisation.
- Asset-management maturity / regulatory — ISO 55000-aligned condition/criticality/ performance and register completeness → the “prove you know your assets” submission (IPART/ESC; the maturity bar from the problem definition).
- Asbestos-cement (AC) safety — the AC register with AS 5488 confidence levels and exposure risk → the spearhead risk story.
- Network / hydraulic — connectivity, diameter, material, roughness for modelling.
This maps straight onto the skin-relative quality model: the same reconciled store answers “good enough for operations?” and “good enough for the regulator?” from different skins.